 Talk to Sales
Talk to Sales Benchmarks
View scores and output across OCR models spanning many document categories.
Want to run these evals on your own documents?
Talk to Sales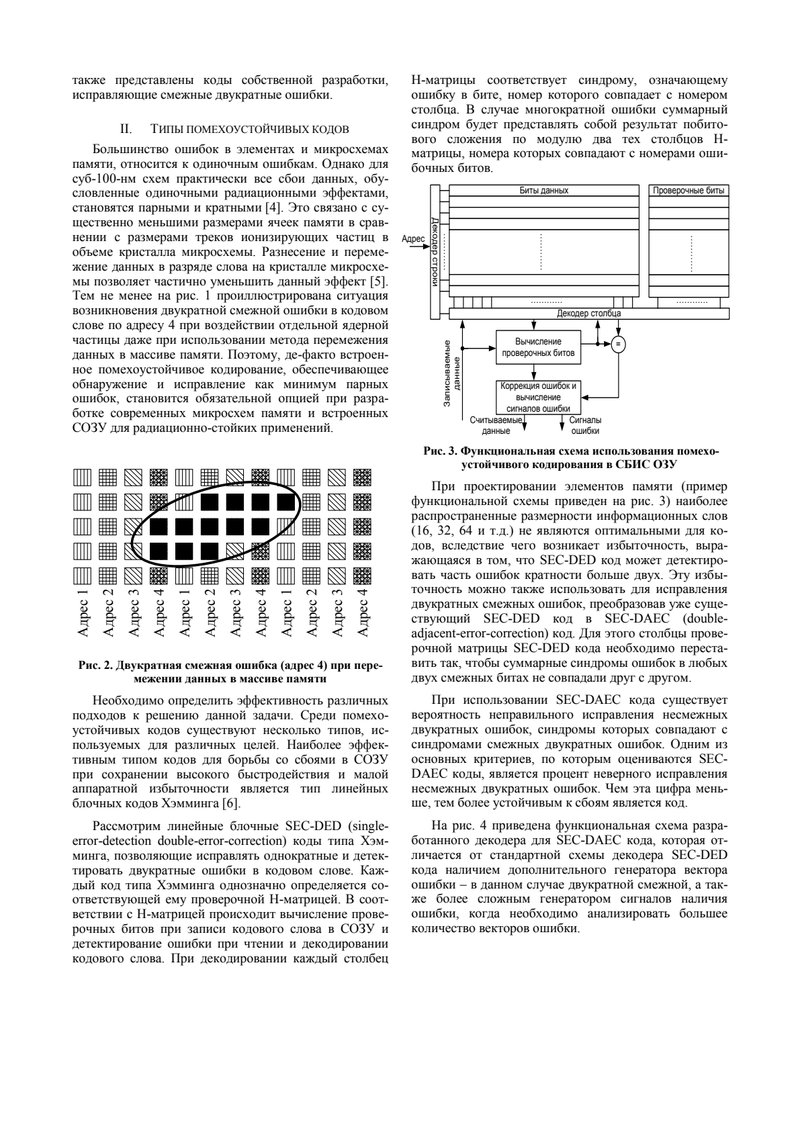
также представлены коды собственной разработки, исправляющие смежные двукратные ошибки.
II. ТИПЫ ПОМЕХОУСТОЙЧИВЫХ КОДОВ
Большинство ошибок в элементах и микросхемах памяти, относится к одиночным ошибкам. Однако для суб-100-нм схем практически все сбои данных, обусловленные одиночными радиационными эффектами, становятся парными и кратными [4]. Это связано с существенно меньшими размерами ячеек памяти в сравнении с размерами треков ионизирующих частиц в объеме кристалла микросхемы. Разнесение и перемежение данных в разряде слова на кристалле микросхемы позволяет частично уменьшить данный эффект [5]. Тем не менее на рис. 1 проиллюстрирована ситуация возникновения двукратной смежной ошибки в кодовом слове по адресу 4 при воздействии отдельной ядерной частицы даже при использовании метода перемежения данных в массиве памяти. Поэтому, де-факто встроенное помехоустойчивое кодирование, обеспечивающее обнаружение и исправление как минимум парных ошибок, становится обязательной опцией при разработке современных микросхем памяти и встроенных СОЗУ для радиационно-стойких применений.

Рис. 2. Двукратная смежная ошибка (адрес 4) при перемещении данных в массиве памяти
Необходимо определить эффективность различных подходов к решению данной задачи. Среди помехоустойчивых кодов существуют несколько типов, используемых для различных целей. Наиболее эффективным типом кодов для борьбы со сбоями в СОЗУ при сохранении высокого быстродействия и малой аппаратной избыточности является тип линейных блочных кодов Хэмминга [6].
Рассмотрим линейные блочные SEC-DED (single-error-detection double-error-correction) коды типа Хэмминга, позволяющие исправлять однократные и детектировать двукратные ошибки в кодовом слове. Каждый код типа Хэмминга однозначно определяется соответствующей ему проверочной Н-матрицей. В соответствии с Н-матрицей происходит вычисление проверочных битов при записи кодового слова в СОЗУ и детектирование ошибки при чтении и декодировании кодового слова. При декодировании каждый столбец
Н-матрицы соответствует синдрому, означающему ошибку в бите, номер которого совпадает с номером столбца. В случае многократной ошибки суммарный синдром будет представлять собой результат побитового сложения по модулю два тех столбцов Н-матрицы, номера которых совпадают с номерами ошибочных битов.

Рис. 3. Функциональная схема использования помехоустойчивого кодирования в СБИС ОЗУ
При проектировании элементов памяти (пример функциональной схемы приведен на рис. 3) наиболее распространенные размерности информационных слов (16, 32, 64 и т.д.) не являются оптимальными для кодов, вследствие чего возникает избыточность, выражающаяся в том, что SEC-DED код может детектировать часть ошибок кратности больше двух. Эту избыточность можно также использовать для исправления двукратных смежных ошибок, преобразовав уже существующий SEC-DED код в SEC-DAEC (double-adjacent-error-correction) код. Для этого столбцы проверочной матрицы SEC-DED кода необходимо переставить так, чтобы суммарные синдромы ошибок в любых двух смежных битах не совпадали друг с другом.
При использовании SEC-DAEC кода существует вероятность неправильного исправления несмежных двукратных ошибок, синдромы которых совпадают с синдромами смежных двукратных ошибок. Одним из основных критериев, по которым оцениваются SEC-DAEC коды, является процент неверного исправления несмежных двукратных ошибок. Чем эта цифра меньше, тем более устойчивым к сбоям является код.
На рис. 4 приведена функциональная схема разработанного декодера для SEC-DAEC кода, которая отличается от стандартной схемы декодера SEC-DED кода наличием дополнительного генератора вектора ошибки – в данном случае двукратной смежной, а также более сложным генератором сигналов наличия ошибки, когда необходимо анализировать большее количество векторов ошибки.